Big Data, as I see it, is understanding one’s preferences in finer detail and then increasing the probability of the choices that fit our preferences to be presented to us. So, there are two things in play – First is profiling and the second is selection.
Let me explain. I like reading books and a certain genre of books. Let’s say I like reading Financial Thrillers written in English that have been published in the last decade or so. Big Data (let’s use it as Service Provider in this write up) keeps collecting data of my behavior, like the titles of the books that I bought, the book review sites or blogs I visited and which of the pages within them I spent time on and what were those pages about etc. Different pieces of data are connected (titles bought, pages visited etc), and data not making sense or not forming a pattern is eliminated (such as the book on sci-fi I bought but that was just once). Based on these, a reading profile is constructed. It is concluded that the probability that I will buy a Financial Thriller is high. This is the profiling part of the Big Data
“Aha, this is a book I need to buy!” – that’s the feeling that the marketer wants to evoke in me. So, they need to select the right books for me – select and present 3, 5 or 10 (not too many, not too less). There are millions of books out there – in different languages, genres, written by different authors, written at different times, rated by different people and so on. From these millions of options, Big Data selects those 3 Financial Thrillers that are most likely to catch my interest or “engage” me. One of which at least I might buy. In a way it is a selection of say 5 from the millions of options.
At this stage Big Data starts doing one more interesting thing – it tries to become bigger and bigger. Why? Only when the number of books is large is the probability that the range of books of my preference gets higher. Finding the 3 books in 2 million is more probable than finding them in 1 million. Big Data keeps trying to grow bigger, expanding services, collaborating, taking over competition or smaller players and so on.
Big Data is similar for different fields, such as e-Commerce, healthcare, social networking and finance. To recap, the two important aspects of Big Data’s success or rather fulfillment of our specific needs are one, good profiling and two, assimilation of data on a massive scale.
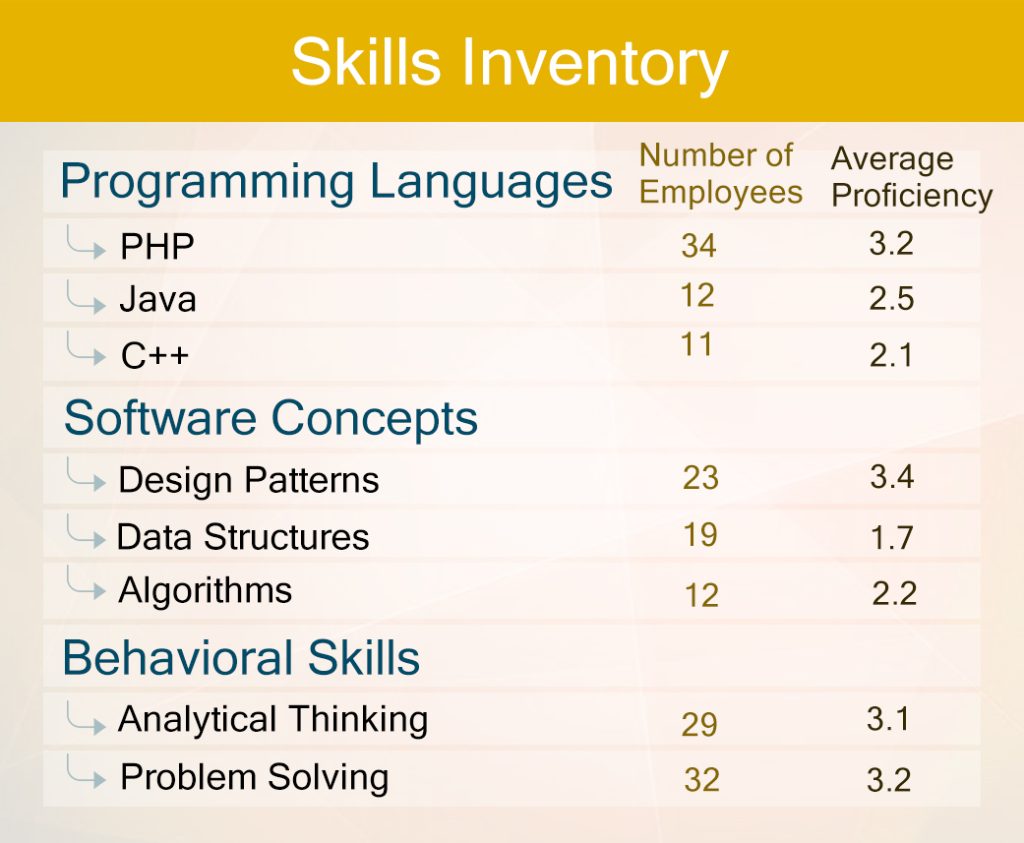
The talent landscape does not have something like this, for the following reasons. A lack of profiling of skills – in a structured manner like the attributes of a product, and a large data pool of skills. Whatever pools of data exist in the HRIS of companies or in job boards are not massive enough. Due to this, the talent landscape cannot benefit from the Big Data movement. Big Data in HR, as it is being often referred, does not necessarily refer to what Big Data is doing in the other domains.
As an attempt to solve at least one of the two problems – lack of profiling and lack of massive data, It’s Your Skills has created a Skills Profile which could be used by anyone and everyone. Find it here <link to skills profile>.
NOTE:
This blog has been written by Ramu G, who heads up the IYS Skills Tech team. He enjoys being completely hands on with day-to-day operations. An engineer from the Indian Institute of Technology at BHU in Varanasi and with an MBA in HR from XLRI in Jamshedpur, his key objectives are conceptualizing and developing ideas for solutions, driving product development and business strategy. A creative and strategic thinker, Ramu has a rich and distinguished career with almost a quarter of a century spent in senior management positions in the IT, FMCG and HR sectors.